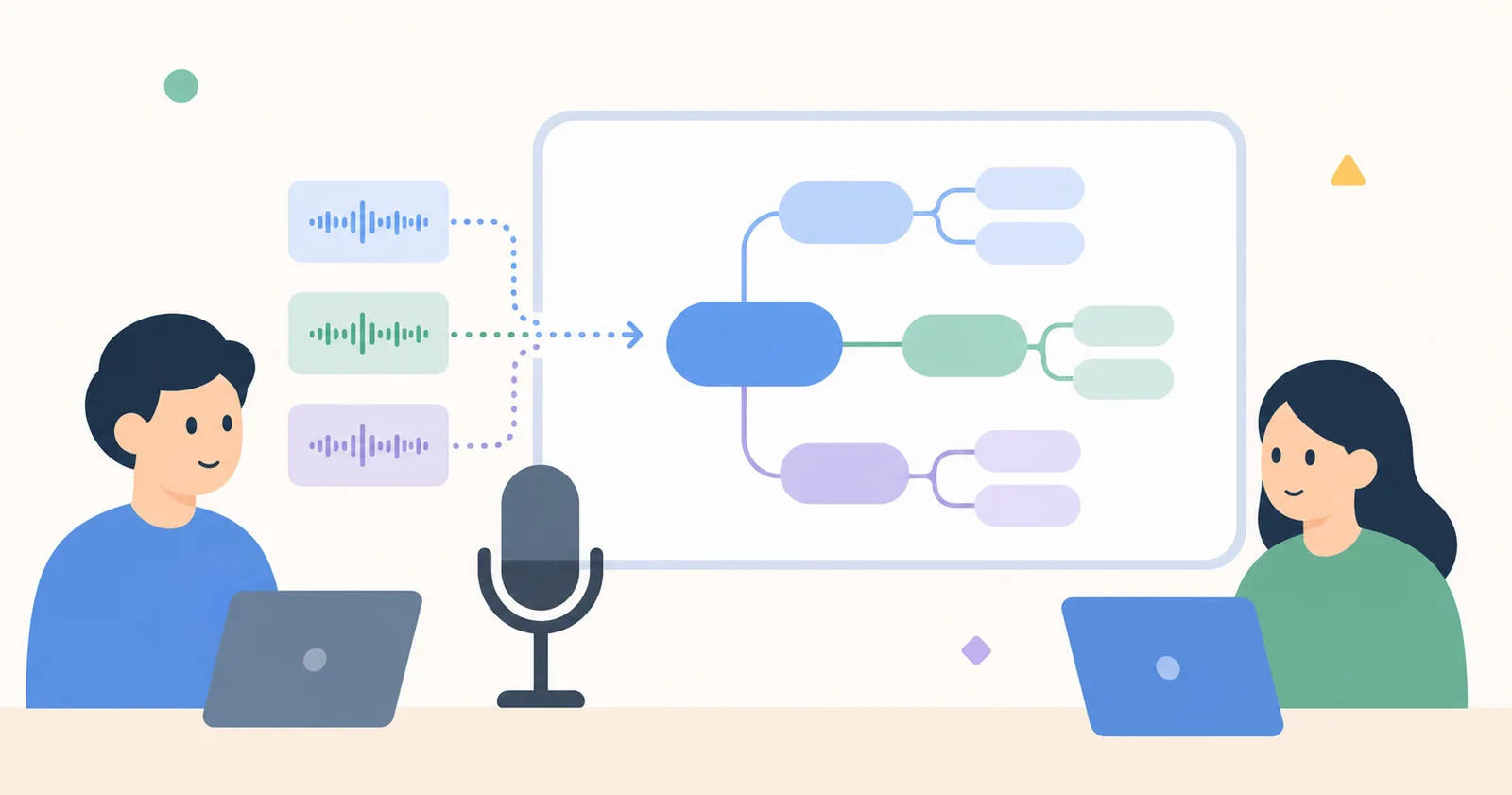
"회의 끝나고 정리하지 마세요. 회의 중에 마인드맵이 만들어집니다." 우리가 Canvas의 회의 기능을 만들 때 잡은 목표였습니다. 200ms 이하 지연으로 자막을 그리고, 동시에 키워드를 추출해 노드로 변환하는 일은 생각보다 까다로웠습니다.
왜 직접 만들었나
OpenAI Whisper API를 그대로 쓸 수도 있었습니다. 하지만 두 가지 문제:
- 한국어 회의 환경(외래어 섞인 기술 회의, 사투리 화자)에서 정확도가 들쭉날쭉
- 음성 → 텍스트 → 키워드 추출까지 직렬로 처리하면 사용자가 체감하는 지연이 1초 이상
그래서 직접 Whisper v2를 서빙하고, 그 위에 우리만의 키워드 추출 파이프라인을 얹었습니다.
아키텍처
[Browser MediaRecorder]
→ WebSocket (250ms chunks)
→ [Whisper Server: canvas-stt.d-sket.dev]
→ 음성 → 텍스트 (스트리밍)
→ KeyBERT 한국어 키워드 추출 (병렬)
→ Embedding (유사 키워드 클러스터링)
→ WebSocket (delta + keywords)
→ [Browser Canvas]핵심은 병렬. 음성이 텍스트로 변환되는 동안 이전 청크의 키워드를 동시에 추출합니다. 직렬로 처리하면 1초가 걸리는 작업이 250ms로 끝납니다.
지연을 줄인 트릭들
- 250ms 청크 — 더 짧으면 정확도가 떨어지고, 더 길면 체감 지연이 커집니다. 한국어에는 250ms가 최적.
- 점진적 출력 — 텍스트가 완성되기 전 단어 단위로 미리 보냄. “안녕…” → “안녕하세…” → “안녕하세요.”
- WebRTC voice activity detection — 무음 구간은 서버로 보내지 않음. 회의의 침묵 시간만큼 트래픽 절약.
처음에는 음성 인식만 잘되면 끝이라고 생각했는데, 사용자 인터뷰를 해보니 “지연이 0.5초 이상이면 신뢰가 깨진다”는 게 핵심이었습니다. 정확도보다 응답성이 더 중요한 영역이 있어요.
— 조부건
화자 분리
회의에서 누가 말했는지 구분하는 일도 마찬가지로 중요합니다. PyAnnote 기반 화자 분리를 실시간으로 돌리되, 처음 30초는 보정 시간이라고 명시합니다. 그 이후엔 화자별 색깔로 자막이 표시됩니다.
키워드 → 마인드맵
추출된 키워드를 어떻게 노드로 만들지가 마지막 퍼즐이었습니다. 단순히 모든 키워드를 노드로 만들면 화면이 금방 가득 차고, 너무 보수적이면 의미가 없죠.
우리 휴리스틱:
- 같은 키워드가 3번 이상 반복되면 노드 생성 후보
- 임베딩 유사도가 0.85 이상인 키워드는 기존 노드에 병합
- 화자별로 색이 다르게 — 누가 자주 언급하는지 한눈에
회의 끝나고 보면 평균 8~15개의 노드가 자동으로 생성되어 있고, 사용자는 위치만 정리하거나 추가 노드를 그리면 됩니다.
다음 단계
다음 분기에는 화상 회의 통합입니다. Zoom·Google Meet의 오디오 트랙을 직접 받아 마인드맵을 생성하는 기능. 회의 도구를 떠나지 않고도 Canvas 노드가 자동으로 쌓입니다.